Discover what people need, love, and dislike by analyzing customer feedback.
3,000+ growth-obsessed teams from 90+ countries
create 5 reports in every 30 minutes at Kimola.
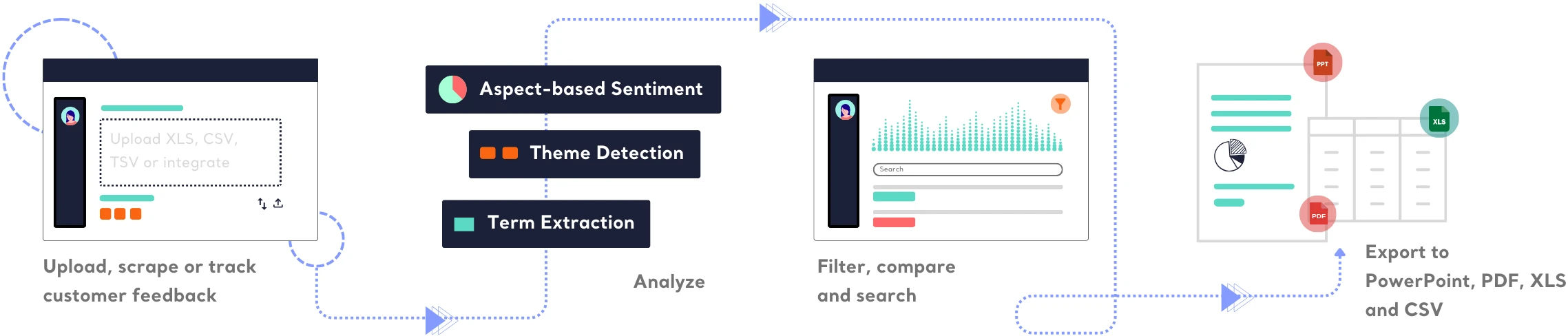
Discover key themes, sentiments, and recurring patterns in customer feedback. Uncover what drives customer decisions and identify challenges that trigger complaints—without manual effort.
Kimola breaks down feedback into themes, assigning sentiment to each—so you see exactly what excites customers and what holds them back.
Automatically classify customer feedback without AI training or manual labelling process. No manual work, so there is no human error.
Analyze customer feedback in multiple languages without the hassle of managing separate datasets.
Kimola requires no AI training to get started. It automatically classifies customer feedback with dynamic labels based on your data—without relying on rigid, pre-defined categories. Need more control? Deploy custom AI models tailored to your business needs or use industry-specific models for high-accuracy classification.
Kimola tracks conversations across social media, news sites, blogs, and forums—keeping you informed about discussions around your product or service. You can also monitor customer feedback by entering links from platforms like Trustpilot, Google Play, and the App Store for continuous tracking.
Kimola collects and organizes mentions by keywords to help you stay informed about your brand and market trends while you keep an eye on your competitors.
Simply enter a link from Amazon, Trustpilot, Tripadvisor, Google Business, App Store, or Google Play, and Kimola will regularly collect and organize new reviews.
Get notified about 🔔 keyword mentions, 👑 influencer involvements, or 🔺 sudden spikes in the data volume. Each email type has a unique emoji in the subject line, so you can recognise the type of update at a glance—without even opening your inbox.
Already collecting customer feedback? Upload datasets directly in Excel, CSV, or TSV formats, or integrate Kimola with Google Sheets, Zendesk, or Intercom for seamless, automated analysis.
Easily upload and analyze customer feedback from Excel, CSV, TSV, or integrate with popular platforms like Intercom, Zendesk, and Google Sheets.
Kimola offers a browser extension that scrapes customer feedback from 30+ sources and uploads it to your account.
Export beautifully designed reports in PowerPoint, PDF, Excel, and CSV formats. Get all classification results, auto-detected themes, and structured insights in a single file—ready to share with the C-suite.
Kimola needs no AI training to classify customer feedback. It automatically generates clusters based on the context rather than using pre-defined labels.
Scraping reviews from leading platforms like Amazon, Google Business, Trustpilot, Tripadvisor, Google Play, and the App Store is a smooth process in Kimola.
Find out how Kimola can improve your feedback analysis process.
Uncover customer needs, likes, and dislikes from product reviews and feedback.
Analyze customer reviews and ratings to optimize online shopping experiences.
Extract insights from social media conversations and online discussions.
Make sense of free-text survey responses with AI-powered analysis.
Understand customer sentiment and concerns from chat and call transcripts.
Identify workplace trends and employee sentiment from internal feedback and reviews.
Kimola is the #1 market research platform for SMBs to discover what people need, love, and dislike by analyzing customer feedback.
Kimola automatically detects key themes, sentiments, and recurring patterns in customer feedback to reveal what drives customer decisions and identify pain points that trigger complaints—without manual effort.
Kimola requires no AI training—it dynamically labels customer feedback based on your data instead of rigid categories. Need more control? Use custom or industry-specific AI models for precise classification.
Kimola monitors social media, news sites, blogs, and forums to keep you informed about discussions around your brand. It also tracks reviews from platforms like Trustpilot, Google Play, and the App Store.
Already collecting feedback? Easily upload datasets or integrate with Google Sheets, Zendesk, or Intercom for seamless analysis.
Kimola transforms customer feedback into structured insights, going beyond generic summaries. It detects key themes, sentiments, and behavioral patterns to provide executive summaries, customer personas, usage motivations, pain points, and SWOT analysis—all backed by real customer data.
Unlike traditional tools, Kimola organizes insights in a structured format, helping businesses make clear, data-driven decisions.
Kimola analyzes customer feedback in 30+ languages without requiring manual segmentation. Its AI processes multilingual datasets seamlessly, delivering structured insights in a unified format. Reports can be generated in English, Spanish, Portuguese, French, German, and Turkish, ensuring clear, actionable insights. You can also filter feedback by language to explore regional trends and customer perspectives.
Kimola is designed for SMBs, startups, and growing brands that need to understand their customers without the high costs and manual work of traditional market research. It’s used for product feedback analysis, e-commerce review analysis, social listening, survey analysis, chatbot conversation analysis, and employee feedback insights.
Simply sign up, connect your data sources, and start analyzing customer feedback instantly. No setup hassle, no coding required—just insights.
Analyze customer feedback in 30+ languages—no AI training needed.
Create a Free Account No credit card · No commitment
Join 3,000+ growth-obsessed teams
from 90+ countries.