How to generate an NLP dataset from any internet source?
Aug 01, 2026 - 11 minute read
Acquiring a high-quality dataset is the cornerstone of any meaningful market research process. The initial dataset's quality, scope, and applicability play a pivotal role in determining the research's feasibility and depth. As a part of the Kimola team, I find myself frequently working with large datasets, often composed of tens of thousands of customer feedback entries. From this prolific experience, I can confidently assert that every single piece of feedback contributes significantly to unveiling consumer insights.
While numerous resources online discuss the importance of collecting and analyzing customer feedback, there remains a scarcity of comprehensive guides on creating an appropriate dataset from scratch. Analyzing raw data effectively begins with constructing a structured and insightful NLP (Natural Language Processing) dataset. Therefore, this article aims to demystify the process of generating an NLP dataset from various internet sources - the critical first step towards robust data analysis and market research.

Before we delve into the technical intricacies, it is important to address a key ethical consideration: this article is crafted to guide readers in creating a sample dataset strictly for research purposes. It's crucial to note that indiscriminately scraping and republishing content from other websites can be illegal and lead to legal repercussions. Always ensure you are in compliance with terms of use and data privacy regulations.
With that said, let's begin by laying the foundation and addressing the basics to make sure we are starting on the right foot and are aligned in our understanding.
What is a dataset?
In its simplest form, a dataset is a compilation of data organized in a structured manner, where each column represents a distinct variable and each row corresponds to an individual record within the dataset. Datasets serve as invaluable tools for researchers and data analysts, enabling them to observe shifts in consumer trends, draw comparisons between varying datasets, and unearth deeper insights into consumer behavior.
Datasets can manifest in a multitude of formats, including numeric, image, audio, or video data. However, at Kimola, our expertise predominantly lies in text data derived from customer feedback. For this reason, this article focuses on creating an NLP dataset specifically through text data.
The text data selected for analysis can either be encapsulated in a singular field or distributed across multiple fields within a dataset. For instance, when dealing with user reviews or news articles, one might choose to analyze the title and body text collectively to gain richer contextual insights. Conversely, datasets might include additional fields that are not subject to text analysis but serve as valuable ancillary attributes in the research process, such as date, time, and links.
Beyond analysis, datasets can also be instrumental in training Machine Learning models. In such scenarios, besides the text data, it is essential for a field to contain specific labels or tags, often seen as positive or negative annotations in the context of sentiment analysis. Within the consumer research industry, a more sophisticated labeling framework is often adopted to classify extensive text data, thereby unlocking valuable insights hidden within customer feedback.
Understanding the structure and purpose of a dataset provides us with the contextual foundation necessary for generating an effective NLP dataset. In the following sections, we will explore the step-by-step process to source and compile such datasets from a variety of internet sources.
Why are datasets important for research?
Datasets are the backbone of any research initiative. They serve as the critical deciding factor in whether a research project moves forward or comes to a halt. The scope, quality, and even the feasibility of research hinge on the data at hand. Every research endeavor demands a unique set of data tailored to specific objectives, thereby underscoring the dataset's pivotal role in defining the parameters and potential outcomes of the study.
A key aspect to consider when constructing an NLP dataset is the diversity of data. Bias can severely compromise the validity of research findings. For instance, constructing a dataset exclusively from consumer complaints on a specific internet platform can skew results toward negative sentiments, ultimately distorting the research outcome. As diligent researchers, striving for balance by sourcing data from a variety of platforms is essential. This diverse approach ensures a more holistic and accurate understanding of public opinion on any given topic.
In addition to variety, consistency is another crucial factor in dataset construction. Whether utilizing publicly available datasets or ones we assemble ourselves, ensuring data relevancy is paramount. It's not uncommon to encounter datasets cluttered with irrelevant information, which can lead to misleading analysis—such as evaluating advertisement text instead of genuine consumer feedback. Such discrepancies can drastically alter the insights drawn from the research.
Furthermore, having the right quantity of data is crucial as well. While there's no universal formula to determine the ideal dataset size, experience and research goals can guide this decision. The scouting stage of data collection is an excellent opportunity to gauge the volume necessary to garner meaningful insights.
Now that we've established the foundational importance and considerations of datasets, it's time to embark on the journey of generating a dataset for an imaginary research project. We will navigate the practical steps required to collect and compile an NLP dataset from diverse internet sources, ensuring robustness and reliability in our research approach.
How do you find the right website for data collection?
The internet hosts an immense array of platforms where people freely express their opinions on a myriad of topics. With such a vast digital landscape, identifying the right website for data collection can seem daunting. However, by following a few strategic tips, you can streamline the process of finding optimal sources for creating an NLP dataset.
1. Define Your Dataset Language
Before you start scouting for data sources, it's crucial to establish the language of your dataset. Most machine learning models are designed to process text in a single language, which means that a model trained to classify consumer opinions in Spanish, for instance, may not perform accurately when applied to English text. Establishing the primary language of your data ensures model compatibility and maximizes the accuracy of your analysis.
2. Perform Targeted Search Queries
Once you've determined the language, tailor your search queries to locate websites that facilitate user-generated content within your domain of interest. For example, you could use queries like "Top e-commerce websites in {country}," "Top forums on {topic}," or "Most influential blogs for {topic}." These queries can lead you to a plethora of resources where individuals actively share opinions relevant to your field of study. Given the vast range of topics and regions, countless articles prioritize different platforms, enabling you to find suitable sources efficiently.
3. Prioritize Date-Stamped Content
When choosing websites, ensure they provide date-time information for each post. The relevance of your research will likely revolve around a specific timeframe; hence, selecting sources that offer accurate timestamps is vital. Date-stamped entries allow you to align your data analysis with specific periods, providing precise insights into trends and shifts over time.
4. Assess Platform Credibility and Activity
Additionally, evaluate the credibility and activity level of potential data sources. Opt for well-established platforms with robust user engagement, as these platforms often generate higher volumes of diverse and genuine feedback. Avoid obscure or inactive websites where user opinions may not reflect broader public sentiments.
By methodically identifying and evaluating potential sources, you can gather high-quality data tailored to your research needs. This approach ensures you lay a solid groundwork for generating an NLP dataset ripe with valuable insights, guiding your analysis towards reliable and actionable conclusions.
How to scrape data from any website?
The most reliable way to scrape data to create an NLP dataset is using a browser extension. After choosing websites to scrape data from, you can install this extension calledInstant Data Scraper on Google Chrome or any Chrome based internet browser. Then the icon of the extension will appear next to the search bar.
How does the Instant Data Scraper work?
Let's say you want to understand the pain points and motivations for mobile app users of Social Networks and you choose to start from analyzing the reviews for the Twitter mobile application on Google Play Store. For this purpose, we navigate to Twitter's Google Play page on our web browser and then we click on the Instant Data Scraper icon next to the search bar. A pop-up window appears as shown below;
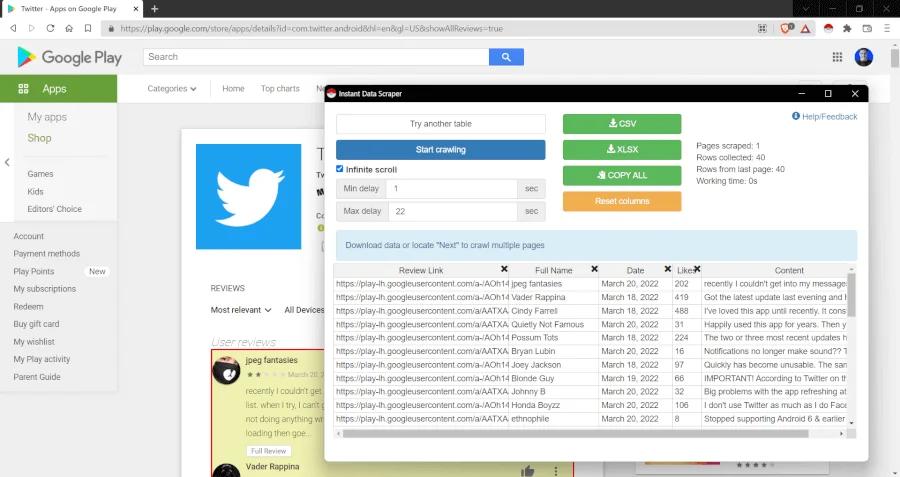
The extension analyzes the HTML content on the web page, detects patterns and captures the variables for each review. Thus, we will have links of the reviews, dates, the counts of likes, name of the users and their reviews, in different columns. This contains pretty much everything in a dataset like the main content to analyze and other helpful attributes like date-time, likes etc.
Google Play has a user interface design that allows you to scroll infinitely. In order to scrape all the data on such websites, all you need to do is check the "Infinite scroll" option on the extension and then click on the "Start crawling" button; the extension will start scrolling Twitter's Google page automatically and scrape all the data.
How to scrape data from multiple pages?
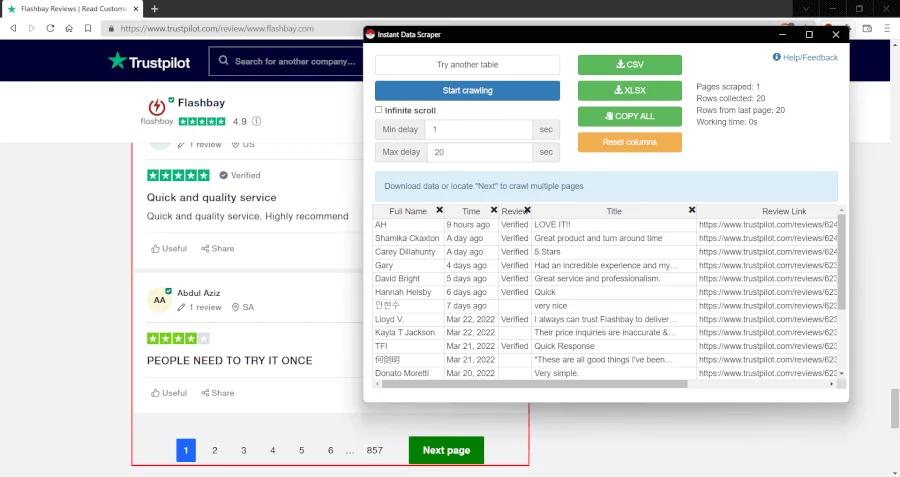
Let's say you need to scrape reviews of a company that has a page on TrustPilot. Unlike Google Play Store, TrustPilot displays reviews on multiple pages rather than an infinitive scroll option. After opening the Instant Data Scraper window by following the same steps I mentioned above, all you need to do is make sure that the "Infinite scroll" option is unchecked and then click the "Locate 'Next' Button" button. When you click the "Next" button on the open website, the extension will detect the button automatically, and when you start the scraping process, it will automatically perform this process and scrape all the data.
Instant Data Scraper will notify you when the entire crawling and scraping process is completed. After this notification, you will be able to download all the reviews in CSV or XLSX formats as your dataset. Just before saving the dataset as a file, you can delete unnecessary columns by clicking the cross on the top corner so you can focus on the data that matters to your research.
CONGRATS! You have generated your first dataset!
How to generate and analyze the Natural Language Processing dataset with Kimola?
In the ever-evolving landscape of market research, utilizing cutting-edge technology is essential for gaining a competitive advantage. Kimola is at the forefront of this transformation, revolutionizing the way customer feedback is turned into actionable market insights. Using advanced AI, machine learning algorithms, and Natural Language Processing (NLP), Kimola processes large volumes of customer feedback to generate insights that drive business growth. This advanced approach allows businesses to easily access the wealth of information available from numerous review platforms.
By automating the analytics process, Kimola eliminates the tedious task of manually reviewing countless feedback entries, offering real-time collection and analysis of user feedback instead. This efficient method not only saves time and resources but also provides the most relevant and current data. Kimola enables data collection from platforms such as Amazon, TripAdvisor, Trustpilot, Google Business, Google Play Store, and the App Store. Its powerful AI quickly identifies patterns, sentiments, and recurring themes in the data, ensuring that vital insights are not overlooked.
Kimola caters to diverse business needs with tailored solutions. For quick, on-the-fly analysis, Kimola is an ideal choice. By entering links from review sites or app stores, the platform dynamically classifies feedback into insightful clusters without the need for prior training. Label selection for data classification in consumer research varies with context; for instance, chocolate bar reviews might be labeled with Taste, Packaging, and Pricing, while bank reviews use labels like Customer Service, Promotions, and Credit Services. Kimola’s dynamic classification technology intuitively understands the context and generates relevant labels, providing nearly instant actionable insights.
For those seeking more comprehensive insights, Kimola offers advanced analytical capabilities. It employs multi-label classification to associate multiple labels with each review, capturing detailed feedback. Sentiment analysis provides additional insights into specific aspects of products or services. Users can also analyze custom datasets by uploading Excel files via a simple drag-and-drop feature on the Kimola homepage.
Kimola’s user-friendly platform excels at distilling valuable insights, such as executive summaries, FAQ lists, and popular customer features, based on collected feedback. These insights can be seamlessly integrated into presentations using accessible performance metrics, pivot tables, and direct comparisons, offering a complete view of analysis results. Once analysis is complete, Kimola facilitates effortless reporting and sharing, with easy export options in formats like PPT, Excel, and PDF.
By leveraging the capabilities of Kimola.com and Kimola, businesses can transform raw feedback into powerful strategic tools, ensuring they remain competitive in an ever-evolving industry landscape. Kimola empowers businesses to convert raw data into insightful narratives, enabling informed decision-making and keeping them at the forefront of industry trends.
To scrape text data and analyze the NLP dataset you generated, you can sign up here to Kimola and create a free account and upload a dataset file.




