- Pretrained AI Models
- /
- Extractor
Entity Extractor
Extract entities with disambiguation, categorize into 35+ classes, beyond what libraries like SpaCy can recognize.
Extract entities with disambiguation, categorize into 35+ classes, beyond what libraries like SpaCy can recognize.
Entity Extractor is a pre-trained AI model that goes beyond traditional Named Entity Recognition (NER). Unlike libraries such as SpaCy, which often miss concept-level entities, Entity Extractor detects and disambiguates even the subtle references hidden in text.
By recognizing entities that conventional NLP libraries overlook, Entity Extractor unlocks new layers of meaning in text data. Whether you are analyzing customer feedback, research articles, or conversations, this model ensures you don’t miss the hidden context that shapes understanding.
For example, “Apple” could refer to the fruit or the technology company, and “Amazon” might mean the rainforest, the river, or the e-commerce giant. Traditional entity recognition often stops at tagging a term, but without disambiguation, the insights remain unreliable.
Entity Extractor doesn’t just recognize entities; it understands them in context. By applying disambiguation, the model ensures that references are correctly interpreted, which is crucial for turning raw text into actionable insights. In customer feedback, this means distinguishing between a complaint about “Apple’s customer service” versus a review praising “apple flavor in a snack.” Without this distinction, analysis could misrepresent customer sentiment, leading to flawed conclusions.
With disambiguation at its core, Entity Extractor delivers more precise, context-aware insights—helping businesses reduce noise, uncover true customer intent, and make decisions based on accurate interpretations of text data.
Entity Extractor doesn’t just identify a name or a concept—it also classifies it into one of 35+ rich categories, ranging from People, Organizations, and Locations to more specific classes like Food and Beverage Products, Health Products, Financial Products, Media, Sports, Music, and Movies. This categorization allows you to see entities in their proper domain, making it easier to connect the dots between what customers are talking about and which areas of your business or industry they relate to.
For example, in customer feedback, a single review might mention a Brand, a Product, and an Emotion in one sentence. By separating these entities into categories, you can quickly understand not just who or what customers are referring to, but also how they feel about it. This multi-dimensional view transforms unstructured feedback into structured insights, enabling more reliable sentiment tracking, competitive benchmarking, and product analysis.
The most common categories used in real-world scenarios include Brands, Products (Food & Beverage, Electronics, Clothing, Personal Care), People, Organizations, Locations, Emotions, and Teams. These categories cover the majority of customer feedback data, but the broader coverage ensures that even niche mentions—such as Awards, Observance Days, or Diseases are not lost.
Kimola brings more to the table than traditional entity extraction by:
With these rich categories, Kimola helps businesses turn raw text into an organized knowledge base—ready for deeper analysis and smarter decision-making.
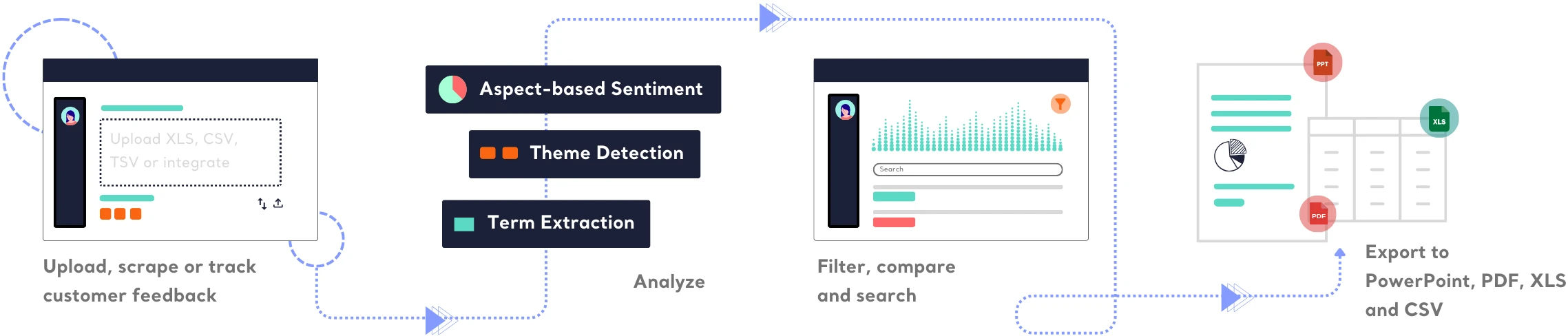
Get started with ready-to-use AI models to analyze customer feedback with the highest accuracy possible.














Kimola offers a super-clean API documentation with code samples to connect your business process with Kimola.
Find out how Kimola can improve your feedback analysis process.
Uncover customer needs, likes, and dislikes from product reviews and feedback.
Analyze customer reviews and ratings to optimize online shopping experiences.
Extract insights from social media conversations and online discussions.
Make sense of free-text survey responses with AI-powered analysis.
Understand customer sentiment and concerns from chat and call transcripts.
Identify workplace trends and employee sentiment from internal feedback and reviews.
Unlike traditional libraries such as SpaCy, Entity Extractor uses disambiguation to distinguish between entities with the same name (e.g., “Apple” as a company vs. fruit). It also classifies entities into 35+ rich categories, beyond the basics.
Yes. It detects not only persons, organizations, and locations but also concepts, industries, events, and products—types of entities often ignored by standard tools.
The model is trained with advanced NLP techniques and curated datasets, ensuring high accuracy in both identifying entities and assigning them to the correct categories.
No. You can use it directly as a pre-trained AI model on Kimola’s platform—just paste your text and analyze. No code required.
Absolutely. If your project requires domain-specific entities, you can train custom AI models on Kimola with your own data and categories.
Turn customer feedback into structured market research in 30+ languages—no AI training needed.
Create a Free Account No credit card · No commitment
Join 3,000+ growth-obsessed teams
from 90+ countries.